Multi-sensor streaming: Clock Synchronization

I am using 2 MetaMotionR Logging Sensors with high frequency streaming for the accelerometer and gyroscope at 100Hz on each sensor, running for 12-15 minutes. These streamed using the Android App.
For these sensors synced in streaming mode, one sensor will log an additional 300-400 data points within the same time frame. This would equate to about a 0.5% internal clock synchronization error for that sampling rate. For the analysis I am performing it is important for the data points to align between sensors.
To solve this I am thinking of assigning time stamps as seen in the image below and then linearly interpolating between them to get the 0, 0.01, 0.02s, etc. values for each sensor that will allow them to be more precisely correlated.
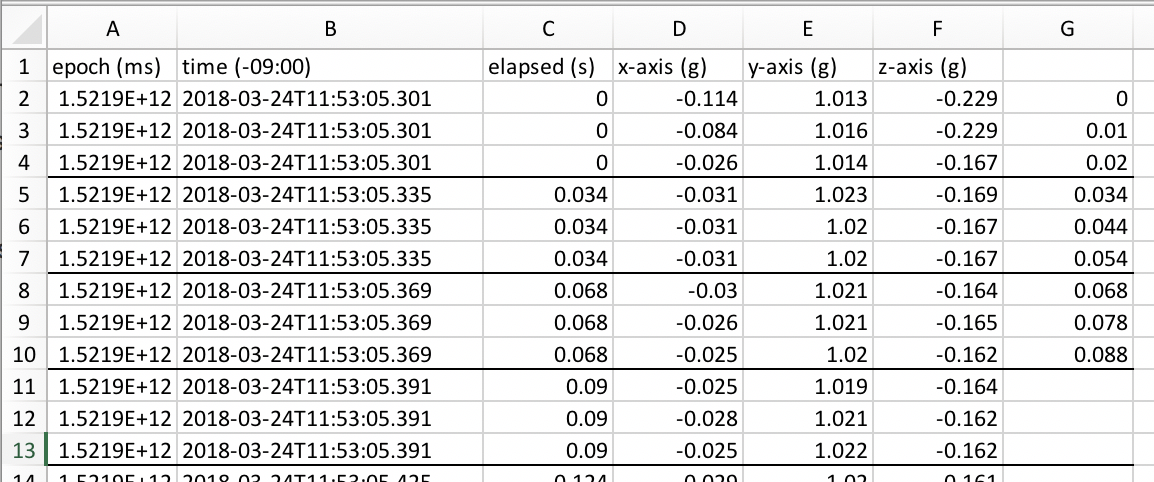
Is this a correct analysis of this issue? Can the data be manipulated in this way reliably without loss of the accelerometer and angular velocity data?
Comments
Timestamp unpacking is discussed here:
https://mbientlab.com/community/discussion/1934/metabase-streaming-timestamps#latest
Align the data from the two sensors such that the initial epoch values have the smallest distance between them, then discard the extraneous data.
Hi Eric,
I am working with JWing on this project. We still have some questions after following the forum discussion you listed and the tutorial listed here: https://mbientlab.com/tutorials/Apps.html#synchronizing-multiple-datasets-in-excel
I've attached outputs from two sensors (ank and pelv sensors) that streamed data (100 Hz) at the same time for a ~20 minute trial to hopefully get us on the same page.
When matching the two sensors based on the epoch time (see 'pelv...' file), as mentioned in your reference, the initial difference is very small (4 ms) which is great, but this grows to ~4000 ms throughout the trial. Notably, the total final epoch times for the last data packet written for each sensor is fairly close (~26 ms). This seems to suggest some inconsistency in the sampling rates of the sensors, which raises a concern about whether we can just match the sensors based on a single point in time and assume they will then be in step with each other because they are sampling at the same rate. It also raises a question about whether we can just delete the extra data since the epoch time stamps for those data are actually still within those from the other sensor (as opposed to just being extra data from before or after the other sensor's epoch times).
Our other question is on restoring the actual time stamps. This seems fairly straight forward in the reference, but we are also running into issue there (may be confounded by the issue above). In the attached 'ank...' data, if I am to incrementally add the idealized time step (0.01 sec for our 100 Hz data) to the trial start in an attempt to restore time stamps that are repeating because of the data packing, I end up with occasional conflicting time stamps (highlighted in red). It seems like there are several ways to approach this (3 of which included in the 'ank..' spreadsheet) each with its pros and cons, but it's not currently clear what the best way to estimate the 'actual' time stamps for each sample.
Please let us know if we are misinterpreting your prior advice and/or any recommendations you have to end up with time-aligned sensors with 'actual' time stamps for each sample.
There will always be time discrepancies when streaming due to not every packet arriving at exactly the same time or in consistent intervals. When streaming, your main metric is samples received i.e. is the number of samples received within a % delta of
odr * sampling time?Looking at the "pelv" file, you have 457 extra (0.5% more) "ank" samples over a ~15min sampling time. Is your algorithm / data processing so sensitive that a fraction of a percent error renders it unusable? Switching to the "ank" file, the difference between the final time of column H (constant 0.01 sampling) and actual elapsed is 7.82s (0.8% error). That is less than the 1% data error on the BMI160 so that's expected.
If you want accurate timestamps, you can either:
Hi Eric,
Thanks for your post. We understand that logging data is preferred to get accurate timestamps, but the time to download the ~15 minute trials from two sensors was too long for the experimental protocol. It would have extended the protocol considerably as multiple ~15 minute walking sessions were conducted within the same session. Also, we recently ran a single 15 minute trial using the logging approach and saw the same behavior (although with unique epoch time timestamps for each sample) for the same two sensors that were used in the files I previously attached.
In an absolute sense, the errors are small (<1%). If the timestamp errors are roughly normally distributed about the desired sampling rate with this small amount of error, then I don't believe it will adversely affect our analyses. However, if the sampling between the two sensors has a bias in the sampling rate that causes a relative drift between the sensors when we implement a constant 0.01 sec sampling assumption, this seemingly small amount of error is relevant because the sensors would be reporting data from different gait strides (stride frequency ~1 Hz --> up to 4-7 strides worth of time misalignment over 15 minutes with improper time alignment).
We would like to use 'ank' data to indicate times of interest for processing the 'pelv' sensor. If we are to believe that the ble packet epoch times are accurate (although potentially inconsistent in terms of when they arrive), would it be more accurate to enforce known start and stop epoch times (first and last ble packet epoch times) and then use a constant spacing for the known number of samples written (see Column L of 'ank' file)? The resulting sampling rate for this data file is ~0.00992 seconds (very close to the 0.01 seconds), but maintains the actual elapsed time of the ble packet epoch timestamps instead of inducing a 7.8 second time shift (obtained when assuming a constant 0.01 sec sampling).
It seems that using this approach on the two sensors would then allow us to resample both sensors' data at consistent timestamps to provide a reasonable estimate (with some error) of time-synced sensors. Does that seem reasonable to you? Please let us know if you identify any issues or have further suggestions.
If adjusting the time based on
# of samples / time elapsedrather than ODR works best for your analysis, then use this method instead.